

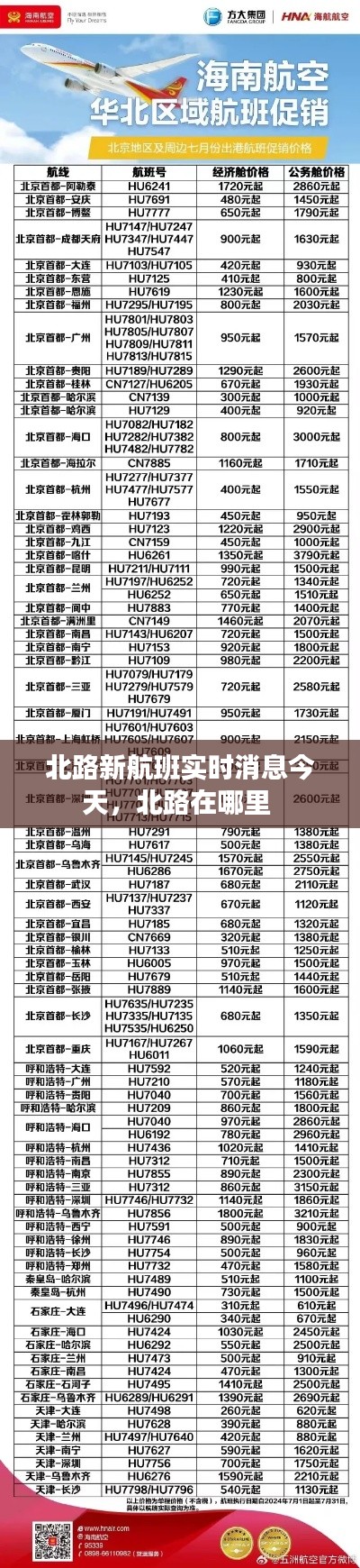




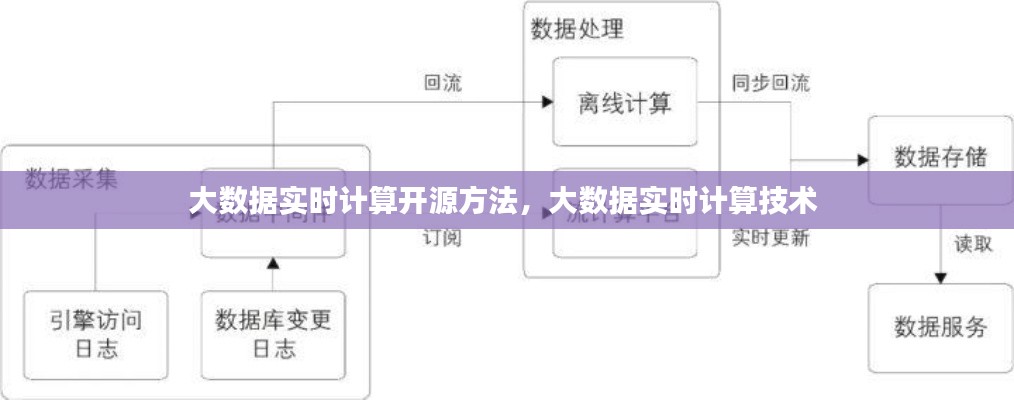
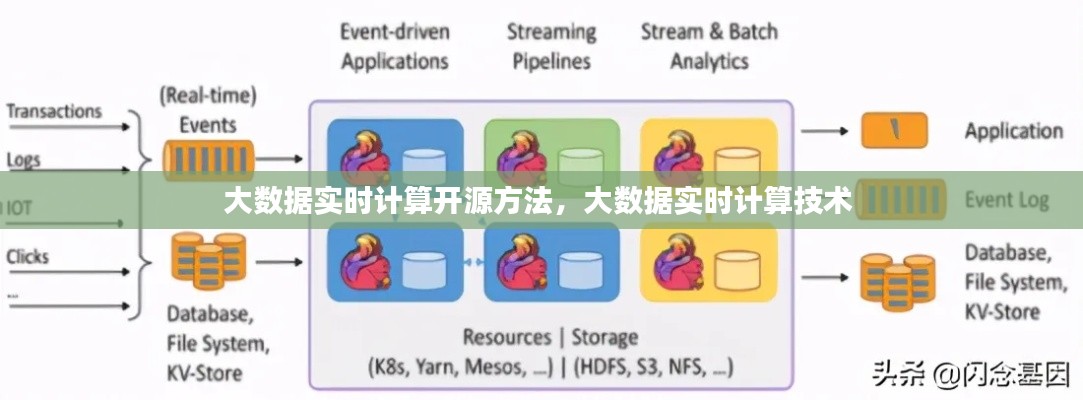
引言
随着互联网技术的飞速发展,大数据已经成为当今社会的重要资源。实时计算作为大数据处理的关键技术之一,能够对海量数据进行实时分析和处理,为企业和个人提供即时的决策支持。本文将介绍几种大数据实时计算的开源方法,帮助读者了解如何利用开源技术实现实时计算。
Apache Flink
Apache Flink 是一个开源的分布式流处理框架,支持有界和无界数据流的实时处理。它具有以下特点:
- 支持事件驱动和批处理模型。
- 提供高效的内存管理和数据交换机制。
- 支持复杂的窗口操作和状态管理。
- 具有良好的容错性和扩展性。
Apache Flink 可以应用于实时推荐系统、实时广告系统、实时监控等领域。
Apache Spark Streaming
Apache Spark Streaming 是基于 Apache Spark 的实时数据流处理框架,它提供了以下特性:
- 与 Spark 的其他组件(如 Spark SQL、MLlib)无缝集成。
- 支持多种数据源,如 Kafka、Flume、Twitter 等。
- 提供丰富的操作符,如 map、filter、reduce、join 等。
- 具有良好的容错性和扩展性。
Apache Spark Streaming 适用于需要与 Spark 生态系统中其他组件协同工作的场景,如实时数据处理、实时分析等。
Apache Storm
Apache Storm 是一个分布式、容错、实时的计算系统,它具有以下特点:
- 支持有界和无界数据流的实时处理。
- 提供丰富的拓扑结构,如 Spout、Bolt、Stream Grouping 等。
- 具有良好的容错性和扩展性。
Apache Storm 适用于需要高吞吐量和低延迟的场景,如实时日志处理、实时分析等。
Apache Kafka
Apache Kafka 是一个分布式流处理平台,它提供了以下特性:
- 支持高吞吐量的消息队列。
- 提供数据持久化和容错机制。
- 支持多种消息传输协议。
Apache Kafka 通常与实时计算框架结合使用,作为数据源或数据输出,实现数据的实时传输和处理。
总结
大数据实时计算开源方法多种多样,本文介绍了 Apache Flink、Apache Spark Streaming、Apache Storm 和 Apache Kafka 这几种常用的开源实时计算框架。这些框架各有特点,适用于不同的场景。在实际应用中,可以根据具体需求选择合适的框架,实现高效、稳定的大数据实时计算。
随着大数据技术的不断发展,实时计算在各个领域的应用越来越广泛。掌握这些开源方法,有助于我们更好地应对实时数据处理的挑战,为企业和个人提供更加智能化的服务。
转载请注明来自江苏安盛达压力容器有限公司,本文标题:《大数据实时计算开源方法,大数据实时计算技术 》








 苏ICP备2020065159号-1
苏ICP备2020065159号-1