





什么是Kafka
Kafka是一种开源的流处理平台,由LinkedIn开发并捐赠给Apache软件基金会。它最初被设计用于LinkedIn的大规模日志聚合,但随着时间的推移,Kafka已经发展成为一个广泛使用的实时数据流处理系统。Kafka的核心功能是支持高吞吐量的数据传输,它允许用户发布和订阅实时数据流。
Kafka实时数据采集
在Kafka中,实时数据采集通常涉及以下几个步骤:
数据源:数据源可以是任何产生数据的系统或服务,如Web服务器日志、数据库变更、传感器数据等。
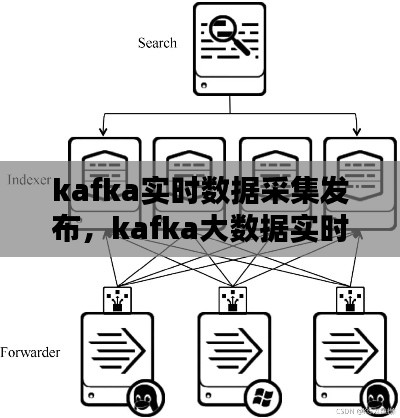
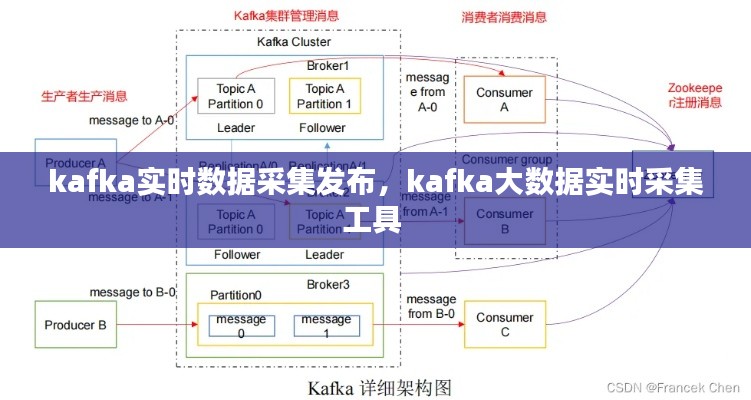
生产者(Producer):生产者是负责将数据发送到Kafka集群的应用程序或服务。生产者将数据组织成消息(Message),并指定主题(Topic)将这些消息发送出去。
主题(Topic):主题是Kafka中的一个分类,类似于数据库中的表。每个主题可以包含多个分区(Partition),每个分区是一个有序的、不可变的消息序列。
数据采集的挑战
在实时数据采集过程中,可能会遇到以下挑战:
高吞吐量:确保系统能够处理大量的数据流,而不会出现性能瓶颈。
数据完整性:确保所有数据都能被正确地采集并传输到Kafka集群。
数据一致性:确保数据在各个消费者(Consumer)之间的一致性。
发布数据到Kafka
一旦数据被采集并组织成消息,生产者就可以将这些消息发布到Kafka集群。以下是发布数据到Kafka的基本步骤:
创建生产者实例:使用Kafka提供的API创建一个生产者实例。
指定主题:为消息指定一个或多个主题。
发送消息:将消息发送到指定的主题。
关闭生产者:完成消息发送后,关闭生产者实例。
以下是一个简单的Python示例,展示了如何使用Kafka生产者发送消息:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
producer.send('test-topic', b'Hello, Kafka!')
producer.flush()
producer.close()数据消费与处理
发布到Kafka的数据可以通过消费者进行消费和处理。消费者可以从Kafka集群中订阅一个或多个主题,并从这些主题中读取消息。以下是数据消费的基本步骤:
创建消费者实例:使用Kafka提供的API创建一个消费者实例。
指定主题和消费者组:为消费者指定要订阅的主题和消费者组。
消费消息:从订阅的主题中读取消息并处理。
关闭消费者:处理完消息后,关闭消费者实例。
以下是一个简单的Python示例,展示了如何使用Kafka消费者读取消息:
from kafka import KafkaConsumer
consumer = KafkaConsumer('test-topic', bootstrap_servers=['localhost:9092'])
for message in consumer:
print(message.value.decode('utf-8'))
consumer.close()总结
Kafka提供了强大的实时数据采集和发布功能,使得大规模实时数据处理成为可能。通过使用Kafka,企业可以构建高效、可扩展的实时数据处理系统,从而更好地利用实时数据来驱动业务决策。
在实施Kafka实时数据采集和发布时,需要注意数据的高吞吐量、完整性和一致性。通过合理配置生产者和消费者,并监控系统性能,可以确保数据流的高效传输和处理。
转载请注明来自江苏安盛达压力容器有限公司,本文标题:《kafka实时数据采集发布,kafka大数据实时采集工具 》






 苏ICP备2020065159号-1
苏ICP备2020065159号-1